-
[계량경제학] 0. Intro + 1. 단순선형회귀모형과 그 해석Studying/[경제] 계량경제학 Econometrics 2024. 7. 2. 16:45
지난 학기에 계량경제학을 수강하면서 처음에는 강의의 흐름을 따라가지 못해
무작정 외우느냐 과목 자체에 흥미가 없었는데 공부를 할 수록 유기성이 보이는 것이
깊게 공부하면 더 잘할 수 있겠고 더 잘하고 싶다라는 마음을 들게 하였다...
그래서 종강을 한 지금 한번 계량경제학을 다시 혼자 공부해볼까하여 이렇게 블로그로 기록을 남겨둔다.
학교 수업을 들을 때는 'Introductory Econometrics 7e' 교재를 가지고 공부했었는데
이번에는 교수님께 추천받은 한치록 교수님의 '계량경제학 강의'를 가지고 공부해보려고 한다.
물론 이 과목을 응용하기 위해서는 영어로 배우는 것이 훨씬 유용하겠지만
그래도 일단 내가 이해해야 응용을 할 수 있으니 수업시간에 배웠던 내용과 이 교재의 내용을 섞어서 열심히 공부해보겠다!
우선 계량 경제학을 공부하기 위해서는 기본 용어들에 대한 이해가 필수적이다.
본인은 아직 계량경제학에 대한 지식이 짧지만 약 3개월 간 공부하면서
계량경제학이라는 과목은 이미 존재하는 데이터를 가지고 변수 간 관계성을 파악하고 추정하는 과목이라고 생각한다.
그렇다면 어떠한 '관계'를 파악하려하는가? 경제/통계학에서 관계란?
- 인과관계: 다른 조건이 동일할 때 (ceteris paribus) 하나의 요소를 변화시켰을 때의 영향
예를 들어, 생활 패턴과 신체적 특성이 모두 동일한 쌍둥이가 있을때 한 아이는 매일 저녁 10시에 취침하게 하고 다른 한 아이는 새벽 2시에 취침하게 한다고 해보자. 그리고 1년 후, 둘 중 오후 10시에 취침하는 아이의 신장이 새벽 2시에 취침한 아이의 신장보다 7cm 가량 차이난다고 한다. 다른 모든 요소는 동일하게 통제해두었다고 하면 위 실험을 통해 이른 취침 시간이 아이의 발육에 도움을 주었다는 것을 알 수 있다.
실생활에서는 보통 한 요소에 다른 요소가 대충 영향을 미쳤다고 보면 두 요소가 서로 인과관계를 가진다고 말하지만 통계학에서는 그 인과관계를 더 정밀하고 통제된 상황에서 판단해서 결론 내려야 하는 것이다.
위에서 언급하였다시피 계량경제학은 이미 존재하는 데이터를 활용하는 학문이라고 생각한다.
그렇다면 그 데이터를 가지고 우리는 어떻게 이용해야할까?
<집단>
- 모집단(Population) - 모수(parameter) - 모평균, 모분산
- 표본(Sample) - 통계량(statistic) - 표본평균, 표본분산
전 세계 모든 인구의 소득수준을 모두 조사하려고 한다. 정확하게 조사하려면 정말 그 어떤 인구도 낙오되지 않고 소득수준을 알아야 할 것이지만 현실적으로 약 80억명 모두에게 소득수준을 물어봐 조사하는 것은 불가능하다. 그래서 우리는 국가 별로, 또 지역 별로, 지자체 별로, 가구 별로 나누어서 일부만 조사하는 방식을 사용한다. 전 세계 인구 중 한국의 소득수준을 조사하기 위해 서울특별시, 경기도, 경상도, 제주도, 충청도, 전라도, 강원도으로 나누어 조사한다. 여기서 전세계 인구가 '모집단', 서울특별시 거주자가 '표본', 전세계 인구의 소득수준이 '모수', 서울특별시 거주자의 소득수준이 '통계량'이 되는 것이다. 위에서 언급하였다시피 전세계 인구의 소득수준은 정확한 값으로 구하지 못한다.(한계) 즉, 모수(parameter)는 우리가 알지 못하는 값이라는 것이다. 대신 서울시 소득수준, 제주시 소득수준, 전라도 소득수준 등의 여러 표본의 통계량(statistic)으로 모수의 값을 추정할 수 있다. 이것이 우리가 앞으로 계속 다룰 회귀모형에 대한 이야기이기도 하다.
- 확률변수(Random Variable): 모집단으로부터 추출을 할 때 값이 변할 수 있는 것
: 위에서 든 예시를 이어보자면 확률변수는 소득수준이 되겠다. 여러 명이 있는 집단에서 한 명의 소득수준을 추출하는 것은 Random하다.
<단순 선형회귀모형과 그 해석>
*선형모형(Linear Model)
: 여타 요소들의 영향이 고정된 상태에서 독립변수와 종속변수의 관계를 1차 선형함수로 설정한 것
ex)
1. 임금 = a + b*학력 + (여타) -> 임금과 학력 간의 단순선형 관계
2. 임금 = a + b*√학력 + (여타) -> 임금과 (√학력) 간의 단순선형 관계
2의 예시의 경우 선형관계가 아니라고 생각할 수 있지만, 단순하게 우변이 a와 b에 대해서 선형이라면 이 모형은 선형모형이라고 볼 수 있는 것이다.
*회귀(Regression)
[ 임금 = a + b*학력 + u ] 라고 모형을 설정하자.
-> u(오차항)이 고정될 때, 학력의 1단위 변화는 임금을 b만큼 증가시킨다. = 임금을 학력에 대해 회귀
*단순선형회귀모형 (Simple Linear Regression Model)
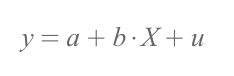
- X: 설명변수, 독립변수, 통제변수, 우변변수, 예측변수, 회귀변수 (independent variable, regressor)
- Y: 피설명변수, 종속변수, 반응변수, 좌변변수, 피예측변수, 피회귀변수 (dependent variable, regressand)
- u: 오차항, 교란항 (error term) : 독립변수 X를 제외한 다른 Y에 영향을 미칠 수 있는 독립변수들
- X와 Y는 데이터를 통해 관측가능하지만(observable) 오차항 u는 관측불가(unobservable)

여기서 β들은 우리가 정확한 값을 알지 못하는 '모수(parameter)'이므로 문자를 β로 통일한다.
- β_0: X가 0이고 u가 0일때의 Y값(절편)
- β_1: X가 Y에 미치는 인과적 영향
*인과적 영향과 평균적 영향
- 인과적 영향: 위에서 언급하였다시피 독립변수가 종속변수에 미치는 정도, 즉 독립변수의 계수를 의미
- 평균적 영향 --> 조건부 평균을 이용
: E( Y | X ) = a + bX (*E(u|x)=0인 경우에*)
=> 'E(u|x)=0' 을 만족할 경우 인과적 영향과 평균적 영향이 동일하게 된다.
<로그와 증가율>
- 자연상수 e

- x의 변화가 아주 작다면, 그 구간 내의 log(x)의 모양은 거의 선형에 가깝다.
- log(x)가 0.01만큼 증가 ≈ x가 1% 증가
- log(x)가 d 만큼 증가 ≈ x가 100*d% 증가
- ex) log(임금)이 0.023만큼 증가 ≈ 임금 자체는 2.3% 증가
- 실제 비율증가 > 로그값 증가분
- x의 변화가 작지 않다면, 위에서 사용한 근사적 표현은 더이상 불가
- log(x)가 [ a -> a+d ] 만큼 증가하였다면
- x는 [ e^a -> e^(a+d) ] 만큼 증가
- 실제 비율 증가 < 로그값 감소분
*단순선형회귀모형과 로그 증가율

+ △u=0 라면,
X가 한단위 증가 = Y는 β_1 단위 증가

+ △u=0 라면,
log(x)의 0.1 증가 = y의 0.1*β_1 단위 증가
= x의 10% 증가와 근사적으로 유사 = x의 10% 증가는 y의 약 0.1*β_1 단위를 증가시킴

+ △u=0 고 β_1값이 작을때,
x이 한단위 증가 = log(y)를 β_1만큼 증가 = y를 100*β_1%만큼 증가

+ △u=0 라면,
log(x)가 0.01 증가 = log(y)가 0.01*β_1 증가
x가 1%증가 = y가 β_1% 증가
*x가 1% 증가할 때 y가 a% 증가하면, a는 'X에 대한 Y의 탄력성'이다.*

*로그는 측정 단위의 변화를 무력화 시킨다!*

새로운 y'가 y의 단위를 변화시킨 값이라고 해도 결국 로그를 통해서 y의 계수인 c는 새로운 회귀식에서 절편 값으로 포함되기 때문에 x의 계수 β_1값 자체에는 영향을 미치지 않는다. = y의 측정단위가 바뀐다고 해서 β_1의 값에 영향을 미치지 않는다.
------
아직 배워가는 학부생이라 부족한 점이 많습니다.
수정해야할 부분이나 새로운 아이디어에 대한 의견이 있으시다면 자유롭게 댓글 남겨주세요 :)
읽어주셔서 감사합니다!